

Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- CHEMISTRY
- 예배
- 찬양
- Software Engineering
- 혼자공부하는sql
- QT
- 일반화학
- 날솟샘
- 웹개발
- 설교
- 프론트엔드
- 전산전자공학부
- csee
- 한동대학교
- 어노인팅
- GLS
- 화학
- FE
- 데이터베이스
- 유태준교수님
- typeScript
- 날마다 솟는 샘물
- CCM
- dbms
- 글로벌리더십학부
- SQL
- 묵상
- Database
- SQLD
- 남재창교수님
Archives
- Today
- Total
멈추지 않는 기록
[혼자공부하는SQL] 15강 본문
728x90
06-1. 인덱스 개념을 파악하자
1. 인덱스의 개념
- SELECT를 사용해서 테이블을 조회할 때 결과를 빠르게 도출하도록 도와주는 기능이다.
- 인덱스가 반드시 필요한 것은 아니지만, 실무에서는 데이터의 양이 엄청 많기 때문에 인덱스가 필요하다
1) 인덱스의 문제점
- 무리하게 많이 사용할 때, 더 느려지거나 시스템에 문제가 생기는 경우가 있다.
- 필요 없는 인덱스를 만드는 바람에 데이터베이스가 차지하는 공간만 더 늘어나고, 인덱스를 이용해서 데이터를 찾는 것이 전체 테이블을 찾아보는 것보다 느려진다.
2) 인덱스의 장점과 단점
(1) 장점
- SELECT문으로 검색하는 속도가 매우 빨라진다.
- 그 결과 컴퓨터의 부담이 줄어들면서 결국 전체 시스템의 성능이 향상된다.
(2) 단점
- 인덱스도 공간을 차지해서 데이터베이스 안에 추가적인 공간이 필요하다.
- 대략 테이블 크기의 10% 정도의 공간이 추가로 필요하다.
- 처음에 인덱스를 만드는 데 시간이 오래 걸릴 수 있다.
- 찾아보기가 없는 책에 새로 찾아보기를 만드는 것과 마찬가지로 작업 시간이 필요하다.
- SELECT가 아닌 데이터의 변경 작업(INSERT, UPDATE, DELETE)이 자주 일어나면 오히려 성능이 나빠질 수 있다.
2. 인덱스의 종류
- 클러스터형 인덱스 (Clustered Index)
- ex. 영어 사전 (책 자체가 인덱스)
- 보조 인덱스 (Secondary Index)
- ex. 책의 뒤에 찾아보기가 있는 일반적인 책 (책에 따로 있는 인덱스)
1) 자동으로 생성되는 인덱스
- 클러스터형 / 보조 인덱스 중에 하나가 생성된다.
(1) 예시1
CREATE TABLE member
(
mem_id CHAR(8) NOT NULL PRIMARY KEY,
mem_name VARCHAR(10) NOT NULL,
mem_number INT NOT NULL
)- PRIMARY KEY로 지정된 mem_id에 클러스터형 인덱스가 자동으로 생성된다.
- mem_id가 영어사전처럼 a~z로 정렬이 된다.
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울', '02', '11111111', 167, '2015.10.19');
INSERT INTO member VALUES('BLK', '블랙핑크', 4, '경남', '055', '22222222', 163, '2016.08.08');
INSERT INTO member VALUES('WMN', '여자친구', 6, '경기', '031', '33333333', 166, '2015.01.15');
INSERT INTO member VALUES('OMY', '오마이걸', 7, '서울', NULL, NULL, 160, '2015.04.21');
INSERT INTO member VALUES('GRL', '소녀시대', 8, '서울', '02', '44444444', 168, '2007.08.02');
INSERT INTO member VALUES('ITZ', '잇지', 5, '경남', NULL, NULL, 167, '2019.02.12');
INSERT INTO member VALUES('RED', '레드벨벳', 4, '경북', '054', '55555555', 161, '2014.08.01');
INSERT INTO member VALUES('APN', '에이핑크', 6, '경기', '031', '77777777', 164, '2011.02.10');
INSERT INTO member VALUES('SPC', '우주소녀', 13, '서울', '02', '88888888', 162, '2016.02.25');
INSERT INTO member VALUES('MMU', '마마무', 4, '전남', '061', '99999999', 165, '2014.06.19');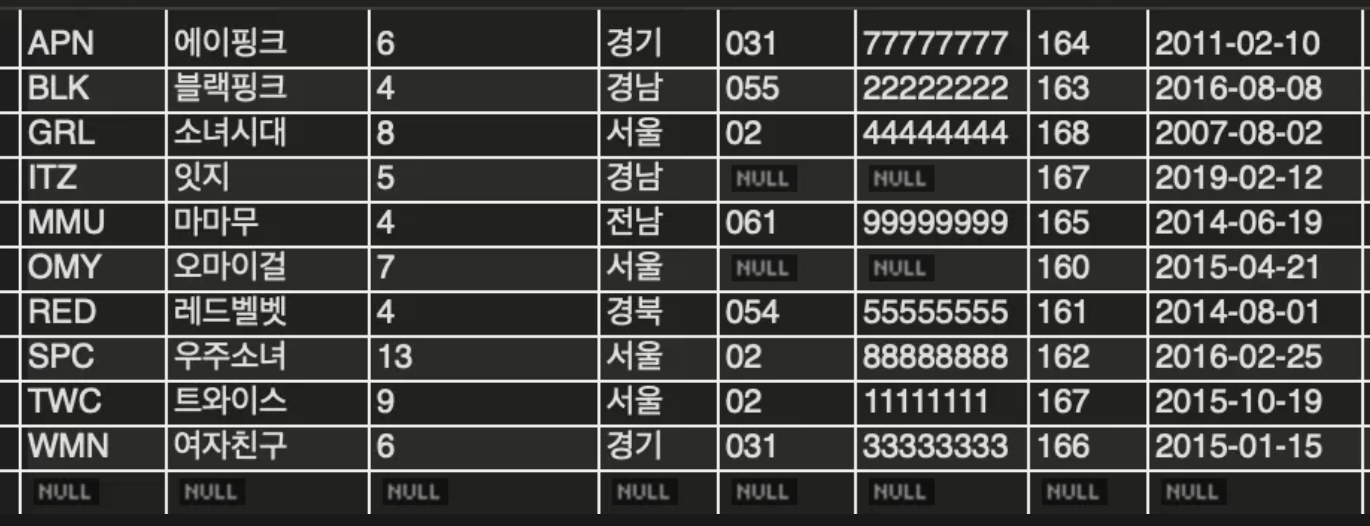
- 입력한 순서와 다르게, SELECT문의 검색 결과는 다른 순서를 가지고 있다.
- PRIMARY KEY로 지정된 mem_id가 클러스터형 인덱스로 자동으로 생성되었기에, 오름차순으로 자동 정렬된다.
(2) 예시2
-- 테이블 생성
CREATE TABLE table1(
col1 INT PRIMARY KEY,
col2 INT,
col3 INT
);
-- 테이블의 인덱스 정보 보는 함수
SHOW INDEX FROM table1;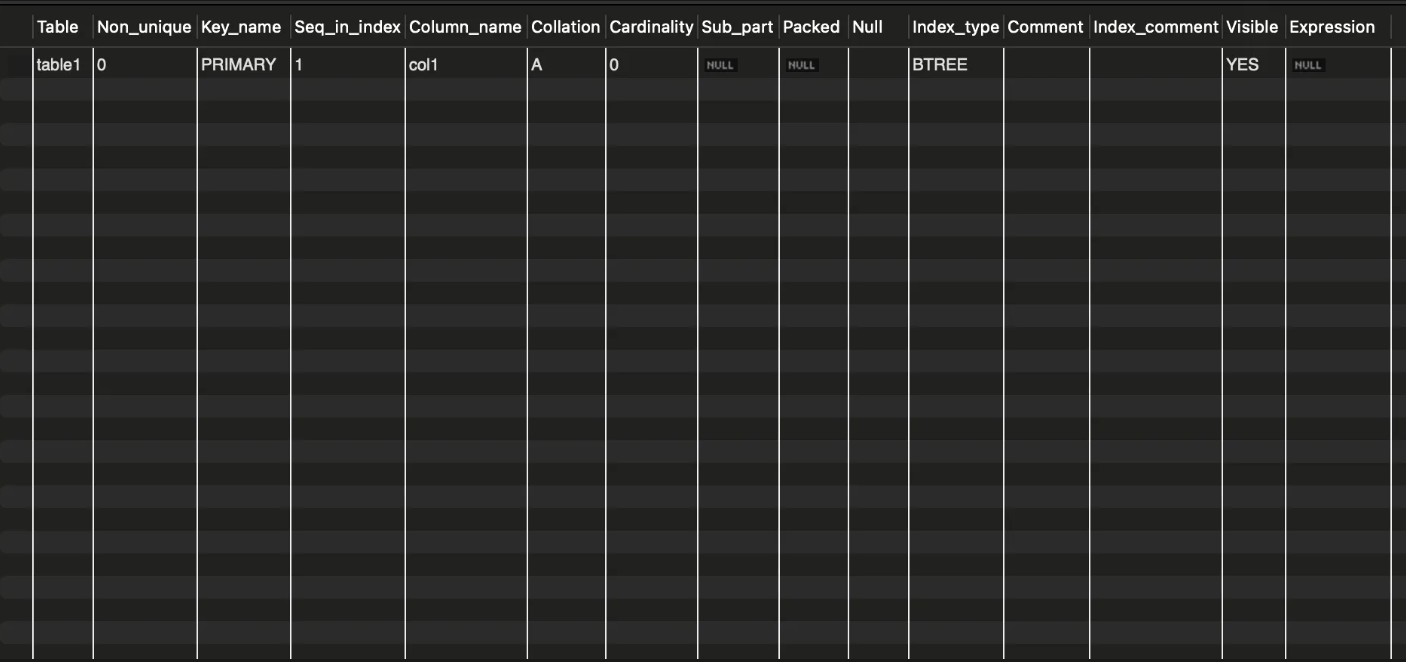
- Table : 테이블 명
- Non_unique : 유니크하지 않은지 (0 : false, 1 : true)
- Key_name : 지정한 키의 종류
- Column_name : 키가 지정된 열의 이름
-- 테이블 생성
CREATE TABLE table2(
col1 INT PRIMARY KEY,
col2 INT UNIQUE,
col3 INT UNIQUE
);
-- 테이블의 인덱스 정보 보는 함수
SHOW INDEX FROM table2;
- col2, col3가 보조 인덱스가 된다.
2) 자동으로 정렬되는 클러스트형 인덱스
(1) 예시
-- 기본 세팅
USE market_db;
DROP TABLE IF EXISTS buy, member;
CREATE TABLE member
(
mem_id CHAR(8),
mem_name VARCHAR(10),
mem_number INT,
addr CHAR(2)
);-- 인덱스 없이 입력한 경우
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울');
INSERT INTO member VALUES('BLK', '블랙핑크', 4, '경남');
INSERT INTO member VALUES('WMN', '여자친구', 6, '경기');
INSERT INTO member VALUES('OMY', '오마이걸', 7, '서울');
-- 결과 출력
SELECT * FROM member;
- 정렬 없이, 입력한 순서대로 보여진다.
-- mem_id에 PRIMARY KEY를 지정하여 클러스터형 인덱스 생성
ALTER TABLE member
ADD CONSTRAINT
PRIMARY KEY (mem_id);
-- 결과 출력
SELECT * FROM member;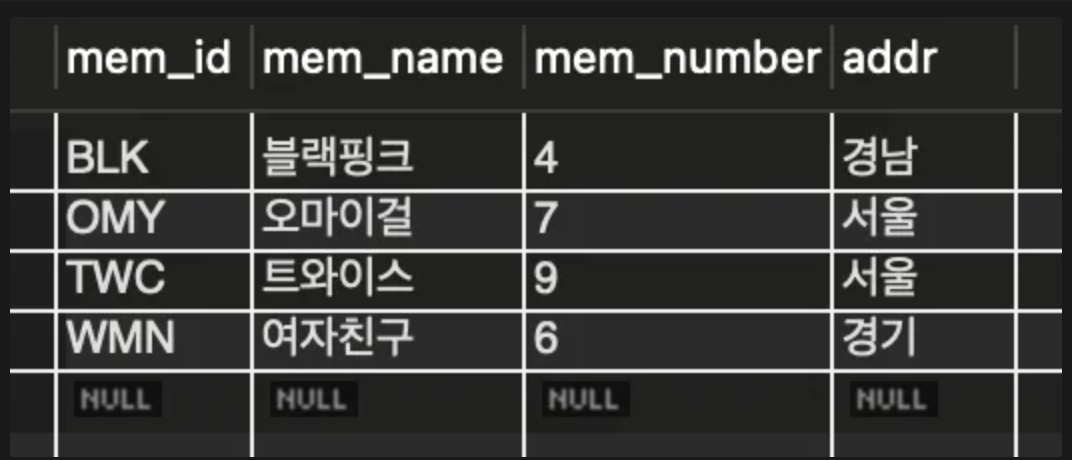
- 클러스터형 인덱스로 지정된 열(mem_id)을 기준으로 정렬이 된다.
-- 기본키 제거
ALTER TABLE member DROP PRIMARY KEY;
-- mem_name에 PRIMARY KEY를 지정하여 클러스터형 인덱스 생성
ALTER TABLE member
ADD CONSTRAINT
PRIMARY KEY(mem_name);
-- 결과 출력
SELECT * FROM member;
- 클러스터형 인덱스로 지정된 열(mem_name)을 기준으로 정렬이 된다.
-- 새로운 값을 입력
INSERT INTO member VALUES('GRL', '소녀시대', 8, '서울');
-- 결과 출력
SELECT * FROM member;
- 새로운 값을 넣어도, 클러스터형 인덱스로 지정된 열(mem_name)을 기준으로 정렬이 된다.
3) 정렬되지 않는 보조 인덱스
- 고유 키로 지정하면, 보조 인덱스가 생성된다.
- 보조 인덱스는 테이블에 여러 개 설정할 수 있다.
(1) 예시
-- 기본 세팅
USE market_db;
DROP TABLE IF EXISTS buy, member;
CREATE TABLE member
(
mem_id CHAR(8),
mem_name VARCHAR(10),
mem_number INT,
addr CHAR(2)
);
-- 인덱스 없이 입력한 경우
INSERT INTO member VALUES('TWC', '트와이스', 9, '서울');
INSERT INTO member VALUES('BLK', '블랙핑크', 4, '경남');
INSERT INTO member VALUES('WMN', '여자친구', 6, '경기');
INSERT INTO member VALUES('OMY', '오마이걸', 7, '서울');
-- 결과 출력
SELECT * FROM member;-- mem_id에 고유 키 지정
ALTER TABLE member
ADD CONSTRAINT
UNIQUE (mem_id);
-- 결과 출력
SELECT * FROM member;- 책 뒤에 찾아보기라는 개념을 만들었을 뿐, 결과가 바뀌지는 않는다.
(2) 여러 개의 고유 키 지정하는 방법
-- mem_name에 고유 키 지정
ALTER TABLE member
ADD CONSTRAINT
UNIQUE (mem_name);
-- 결과 출력
SELECT * FROM member;- 그냥 또 지정해서 추가해주면 된다.
-- 추가로 mem_name에 고유 키 지정
ALTER TABLE member
ADD CONSTRAINT
UNIQUE (mem_name);
-- 결과 출력
SELECT * FROM member;
- 정렬 없이, 맨 아래에 행이 추가된다.
728x90
'웹 개발 > MySQL' 카테고리의 다른 글
| [혼자공부하는SQL] 17강 (0) | 2025.02.26 |
|---|---|
| [혼자공부하는SQL] 16강 (0) | 2025.02.26 |
| [혼자공부하는SQL] 14강 (0) | 2025.02.19 |
| [혼자공부하는SQL] 13강 (1) | 2025.02.19 |
| [혼자공부하는SQL] 12강 (0) | 2025.02.19 |
'웹 개발/MySQL' Related Articles
more



